
2023年12月6日にENECHANGE株式会社の主催にて「耐障害性向上・パフォーマンス改善・負荷軽減を実現する?事業を支えるSREのノウハウを共有」というテーマでのエンジニア向けイベントをオンライン開催しました。
テックベンチャーであるアソビュー株式会社(以下、アソビュー)・Chatwork株式会社(以下Chatwork)・ENECHANGE株式会社(以下ENECHANGE)のSREエンジニアが登壇し、事業特性に合わせてシステムを安定稼働させながら成長を支えていく各社の取り組みについてお話ししていただきました。
本記事ではイベントでの各登壇者のお話をサマライズ版でお届けします。
(執筆者:菅谷望)
アソビューSREで実施した各種最適化の視点について
登壇者: 鈴木 剛志さん(アソビュー株式会社 SREユニット ユニットリーダ)

アソビューについて
アソビューは、「生きるに、遊びを。」をミッションにチケットの電子販売や、レジャー施設や体験事業者向けの業務支援ツール、地方自治体向けの業務改善サービスを提供しています。
2022年8月実績において、月間PV数3,800万、会員数1,000万人を誇る遊び予約サイト「アソビュー!」では、遊園地やテーマパークのチケット、温泉の入場券といった遊びの選択肢を広げるチケットを豊富に取り揃えています。

安定稼働する上で、余剰リソースを見つけていくための視点
システムの性能限界は、ハードウェアのスペックやソフトウェアの設計によって決まります。この上限を意識しながら、サービスの運用に支障がないかを見極めながら運用していく必要があります。
1年前の課題は、以下の2点でした。
- インフラのスペックの見積もりが甘く、過剰なリソースで運用していた
- 過剰なリソースが使われているために、サービスの成長に伴う限界が見えにくく、リスクのある運用を行っていた
これらの課題を解決するために、まず、ビジネス上重要な指標を特定し、その指標の性能限界と必要なインフラスペックの相関を整理しました。これにより、あるインフラスペックでどの程度の処理を捌けるかを把握することができました。
余剰リソースをどのような手法で削減したか
安定稼働基準を基にしたインフラコストの最適化
アソビューでは、人気チケットの発売直後に負荷が急上昇する傾向があります。ただし、このスパイクは平常時の5倍以内に収まるという傾向があることがわかりました。この傾向を踏まえて、通常運用時に5倍のスパイクに耐えられるようインフラを最適化し、安定した稼働を確保しました。
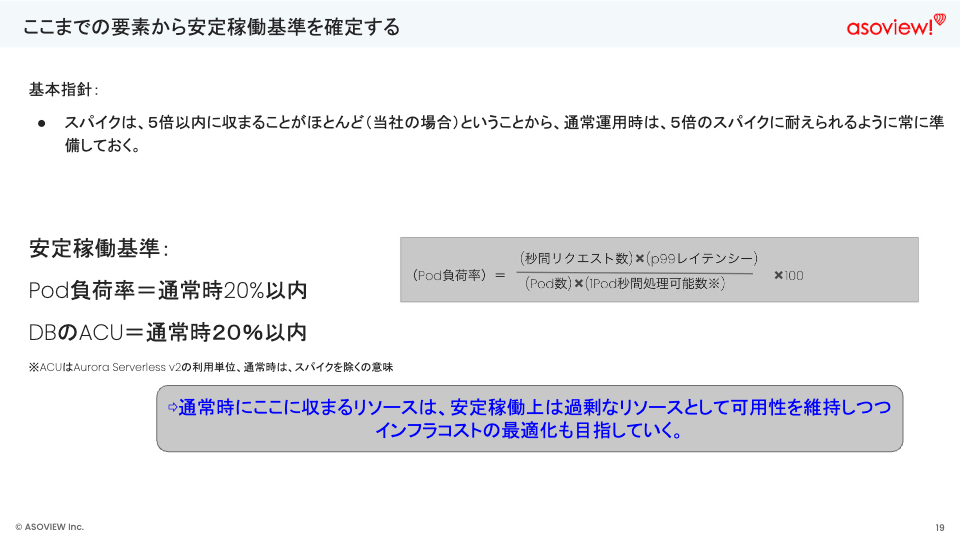
また、人気チケットを購入しようとするユーザーの中には、一定の比率で発売日の少し前に様子を見に来るという行動を取ることが普段の観察結果からわかりました。この事前アクセスのトラフィックをベースにして実際の負荷を予想し準備を行うことで、安定したサービスの提供に繋げることができました。
CPU利用率を基にしたインフラコストの最適化
また、時間帯や日付でアクセス数のトレンドが変わるため、スケールが容易な仕組みとして下記の技術を使うことを検討しました。
- Aurora Serverless v2(DB)
- HPA(Kubernetes)
AuroraをServerlessに切り替えたときのコスト比較を行いました。
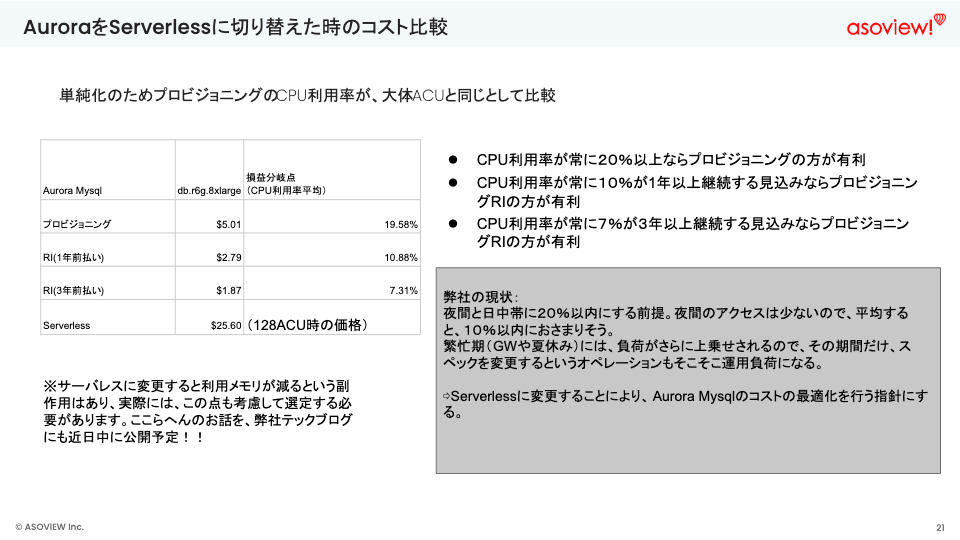
この比較から、下記のことがわかりました。
- CPU使用率が常に20%以上ならプロビジョニングが有利
- CPU使用率が、常に10%以上が1年継続する見込みならプロビジョニングRIが有利
- CPU使用率が、常に7%が3年以上継続する見込みならプロビジョニングRIが有利
アソビューの現状として夜間のアクセスは少なく、平均するとCPU使用率は10%以内に収まることが予想されました。また、繁忙期だけスペックを変更するというオペレーションも運用負荷になるため、AuroraをServelessに変更することでAurora MySQLのコスト最適化を行う方針を取りました。
SRE初心者が急成長しているEV充電サービスの安定稼働にコミットした話
登壇者: 佐々木 徹さん(ENECHANGE株式会社 EV充電サービス事業部 開発チーム)

ENECHANGEについて
ENECHANGEは、「エネルギーの未来をつくる」をミッションに掲げ、エネルギーの4D革命を推進するエネルギーベンチャー企業です。日本・欧州・中東と世界でサービスを展開しています。現在の社員数は約270名です。 採用ページでは、募集職種や応募方法など、採用に関する情報を詳しくご紹介しています。ぜひご覧いただき、ご関心ある方はご応募ください。
engineer-recruit.enechange.co.jp
また、ENECHANGEの事業内容や働き方などに関するニュースやインタビュー記事などもWantedlyやnoteで公開しています。ぜひご覧いただき、ENECHANGEの魅力を知っていただければと思います。
EV充電サービスについて
日本政府が掲げた、「2035年までに新車販売の100%を電動車にする」という目標を背景に、ENECHANGEでは2021年からEV充電エネチェンジというサービスを運営しています。
Webアプリでは、充電スポットの検索や充電の開始・終了などの基本機能に加え、EVドライバーにとって便利な機能を提供しています。
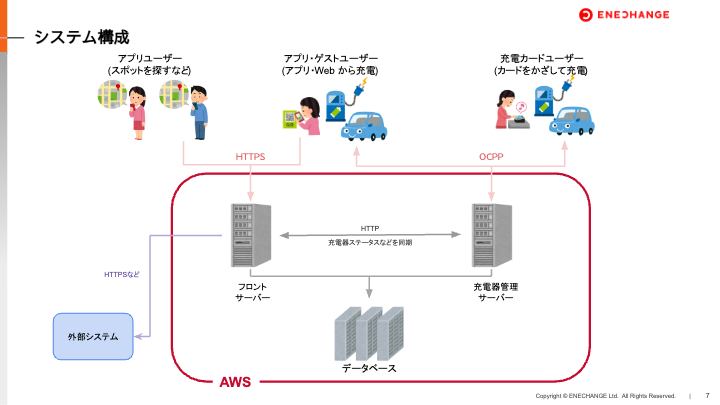
システム構成について
ENECHANGEのEV充電エネチェンジのサーバーは大きく分けて、以下の3種類から構成されています。
- フロントサーバー:アプリのAPIサーバーや、Webページの配信、外部システムとの連携を行う。
- 充電器管理サーバー:充電器1台ずつと接続して、ステータス管理や、充電の開始・終了などの操作を行う。
- データベース:充電スポットの情報や、充電履歴などのデータを保存する。
ENECHANGEのEV充電サービスの充電器管理サーバーは、充電器1台ごとにWebSocketで接続して、充電器の操作や状態に関わるメッセージをJSON形式のデータとして送受信しています。この特徴により、充電器の状態をリアルタイムで把握し、充電の開始・終了などの操作を効率的に行うことができます。
致命的な障害と解決策について
障害の内容と対策
2023年4月、充電器管理サーバがダウンし、多くの充電器で充電ができなくなる障害が発生しました。また、2023年6月にはデータベースがダウンし、いずれの障害でも多くの充電器で充電ができないという致命的な障害が発生しました。この障害の応急措置として以下の対応を行いました。
▼4月の障害
- コンテナ1台あたりの同時接続数緩和のためのスケールアウト&オートスケール導入
- 負荷の原因となっていたバッチ処理の実行頻度を下げた
▼6月の障害
- データベースのスケールアップ
これらの対応により、データベースのCPU使用率は一時的には安定しました。しかし、その後も時折データベースの使用率が急上昇し、アラートが発生していました。さらに検証した結果、使用率が急上昇するタイミングは主に充電器管理サーバのデプロイと重なることが多いことが判明しました。
障害の原因
以下の 3点を理由にデプロイ時にリソース不足に陥ったことが、障害の根本的な原因であると仮説を立てました。
- 充電器管理サーバーのデプロイに伴って旧コンテナが落ち、各充電器とのOCPP(WebSocket)接続が一斉に切断されている
- 各充電器は充電器管理サーバーとの接続が切れると、即時再接続される仕様になっている
- 全充電器からの再接続要求が集中し、充電器管理サーバーがパンクしてしまった
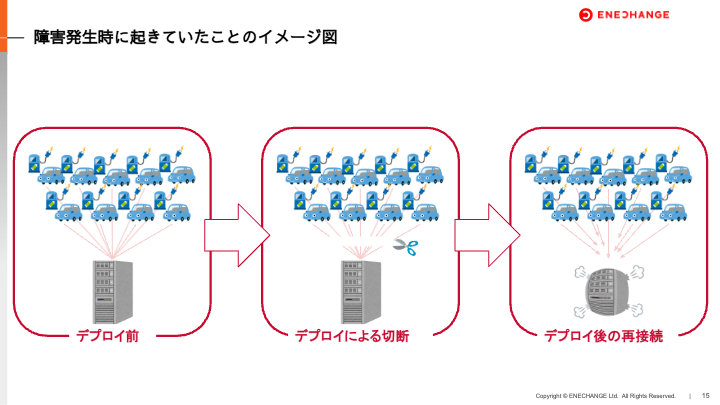
障害への解決策
まず、障害への解決策として以下の2つの方法を検討しました。
1. Exponential Backoffの導入
再接続間隔を指数関数的に後退させるExponential Backoffアルゴリズムの導入を試みました。しかし、充電器管理サーバーのクライアントは充電器そのものであり、クライアント側の改修はメーカーにファームウェア開発を依頼する必要がありました。そうなるとクライアント側での実装が必要になり時間とコストがかかるため、この方法は不採用となりました。
2. Blue/Green デプロイの課題
以前から導入していたAWS CodeDeployを用いたBlue/Green デプロイでは、線形デプロイオプションにより、Blue環境からGreen環境へ設定に応じてトラフィックを置き換えることができます。しかし、以下の問題点が懸念されたため不採用となりました。
- 新規接続のみGreen環境へ誘導されるため、WebSocketで接続済みのクライアントはBlue環境と接続されたままになる。
- Blue環境が破棄されるタイミングで既存の接続が切断され、再接続が集中する。
そこで、再接続が集中しない仕組みを作るためにGraceful Updateの仕組みを独自で実装することにしました。
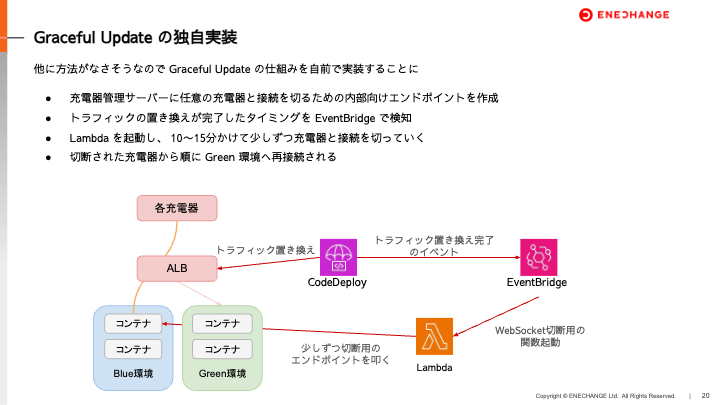
この方法で無事障害を回避することができ、以下のメリットが得られました。
- デプロイ時に高負荷となることがなくなった
- 充電器管理サーバーのデプロイによる障害が発生しなくなった
- デプロイへの心理的ハードルが低くなり、継続的改善のサイクルが早まった
何より、サービスにとって大きな課題をシンプルな方法で解決できたことは、非常に価値のあることだと考えています。
今後の計画について
今後、EV充電インフラサービスの土台を整えるため、以下の3点の取り組みを実施する予定です。
- 3万台を想定した負荷試験を実施して問題点を洗い出す
- 必要に応じてリアーキテクチャを実施する
- SRE業務が属人化しているので、自動化の推進やSRE文化の醸成・浸透をする
Chatwork流Kubernetesの運用方法
登壇者: 桝谷 花世さん(Chatwork株式会社 SRE部)

「Chatwork」とは
「Chatwork」はグループチャットやタスク管理、ファイル管理、ビデオ/音声通話などができるビジネスチャットです。2023年9月末時点では導入社数が42.1万社以上となっています。

SREに求められる3つの目標とは?
ChatworkのSREには、以下の3つの目標が求められます。
【1】コストの最適化
ビジネスをしていく上で利益を上げるためには、インフラコストの削減が求められます。そのため、SREでは、インフラの利用状況を分析し、無駄なコストを削減するための取り組みを行っています。
【2】安定稼働
ビジネスチャットサービスは、ビジネスの重要なインフラとして利用されています。そのため、サービスが停止すると、ユーザーの業務に大きな影響を与えてしまいます。
【3】アジリティの向上
ユーザーのニーズは常に変化するため、ユーザーの要望に柔軟かつ積極的に対応しサービスをアップデートし続ける必要があります。そのため、SREでは、アジリティの向上を実現するための取り組みを行っています。
コストの最適化と安定稼働における課題と解決策について
「Chatwork」はビジネスチャットサービスであり、日中帯のアクセスが集中する傾向にあります。そのため、日中帯のアクセスを想定してサーバーを常時稼働させておくと、夜間帯の稼働率が低下し、コストがかさんでしまいます。
そこで、Chatworkでは、Kubernetesのスケーリング機能を活用して、日中帯のアクセスに合わせてサーバーを自動的にスケールさせています。
しかし、単純にPodをオートスケールすると、以下の2つの課題が生じます。
- Amazon EC2の台数が増加するため、コストが高くなる。
- Podがスケールアウトする際には、Amazon EC2インスタンスの起動に数分かかるため、サービスが不安定になる。
ここからは、それぞれの課題を解決する取り組みについて紹介します。
① EC2の台数が増加するため、コストが高くなる
Amazon EC2の購入オプションの1つである「スポットインスタンス」が以前よりも安定してきたことや、「Chatwork」のアプリがステートレスにできていることから、Amazon EKSのNodeにAmazon EC2スポットインスタンスを導入してコストを削減しています。

② Podがスケールアウトする際には、EC2インスタンスの起動に数分かかるため、サービスが不安定になる
Chatworkでは、社内ツールであるballoonを使ってあらかじめ余剰Nodeを確保しています。
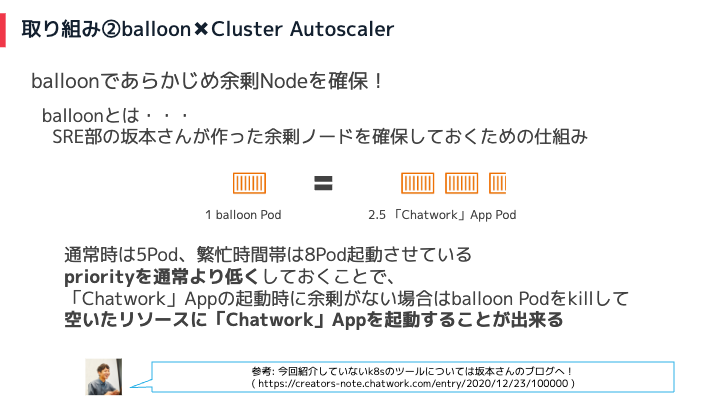
balloon Podを追加すると下記のイメージになります。
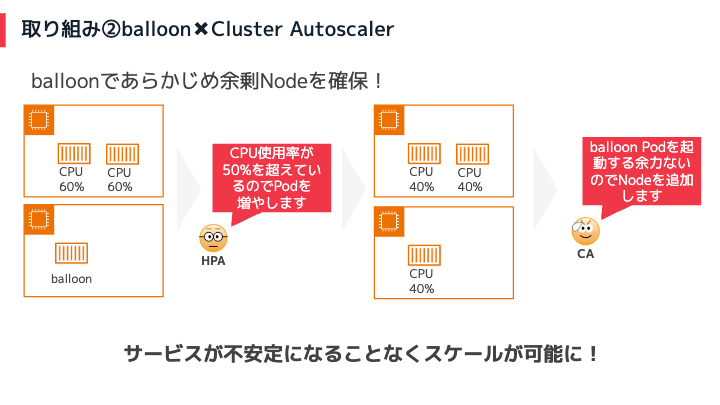
このような仕組みにすることで、Nodeの起動時間を待つことなく、チャットワークのアプリを起動することができます。そのため、サービスが不安定になることなくスケールが可能となっています。
アジリティの向上における取り組みについて
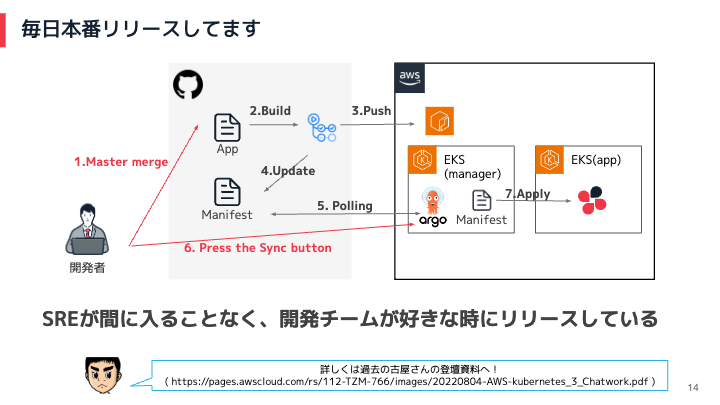
Chatworkでは、開発者がアプリのソースコードをmainブランチにマージすると、自動的にビルド・プッシュ・マニフェストのアップデートが行われます。その後、ArgoCDがポーリングを行い、アプリの状態が正常であることを確認します。
ArgoCDで問題がなければ、開発者はArgoCDの画面からボタンを押すことで、アプリを本番にリリースすることができます。この仕組みにより、SREの介入を必要とせずに、開発チームが好きなときにアプリをリリースすることができます。
アジリティを実現するためには、開発者がスピード感を持って機能開発を進めることが重要です。そのためには、開発者が開発しやすい環境を整えることが求められます。ここからはその取り組みについて紹介します。
- 検証時にSREがボトルネックにならない運用
- 自分専用の使い捨て検証環境の構築
- 開発・本番へのAWSリソースの構築
1. 検証時にSREがボトルネックにならない運用
本番アカウントでは、Amazon Route53の設定変更などの変更を行う際には、必ずSREチームを通す必要がありました。そのため、検証のために設定変更をしたい場合でも、SREチームに依頼して承認を得る必要があり、検証のスピードが遅れるという課題がありました。
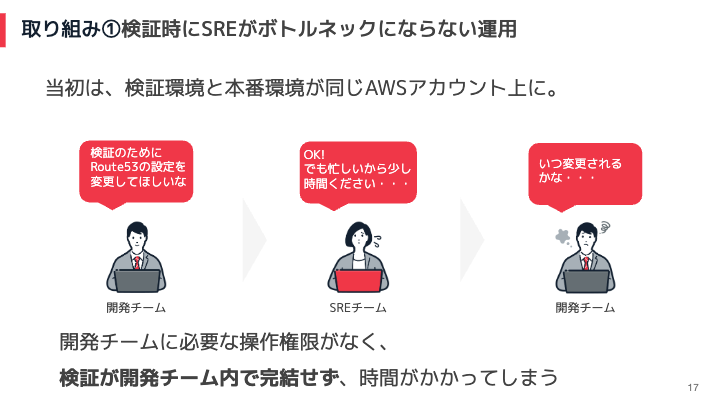
そこで、検証環境と本番環境を分けるとともに、検証環境には開発チームに強い権限を付与しました。この取り組みにより、開発チームは検証のために必要な設定変更を自ら行うことができるようになりました。その結果、開発チームの中で全てを完結することができ、検証のスピードが上がり開発者体験が向上しました。
2. 自分専用の使い捨て検証環境の構築
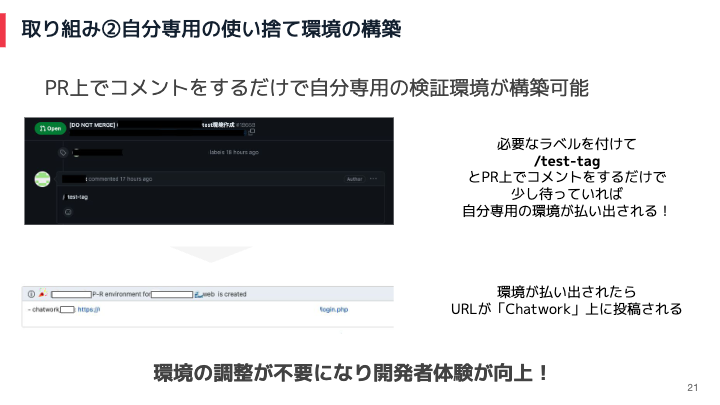
当初は検証用の環境が一つしかなかったので、開発者が検証を行う際には、検証環境を他の開発者が使用していないかどうかを確認する必要がありました。そのため、検証環境の使用タイミングの調整や待ち時間が発生し、開発効率が低下していました。
そこで、Pull Request上でコメントをするだけで自分専用の検証環境が構築できるような仕組みを作りました。これにより環境の調整が必要なくなり、開発者体験が向上しました。
3. 開発・本番へのAWSリソースの構築
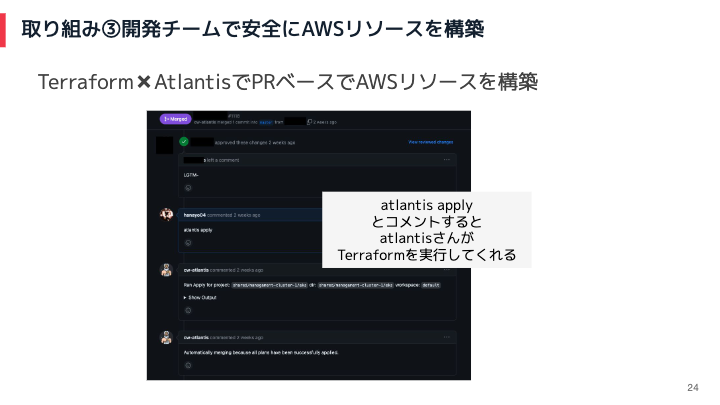
TerraformとAtlantisを使い、Pull RequestベースでAWSリソースを構築できるようにしました。このような仕組みを取り入れることで、SREが関与することなく開発チーム内でインフラ構築を安全にできるようになりました。
以上となります。 イベント概要、ならび各登壇者から共有いただいた資料については以下ページをご確認ください。
今回のイベントでは、各社のSREの取り組みから、事業特性に合わせた具体的な取り組みを共有していただきました。SREは、ユーザー体験とビジネス成長の狭間で常にバランスを取る必要があります。イベント参加者の方々にも、現場で問題に直面する難しさや魅力を感じていただけたのではないでしょうか。本記事が、エンジニアの皆さんにとっての実践的な学びや、キャリア形成に役立てば幸いです。