こんにちは! ENECHANGEで働いているishibashi(id:rubita_isi)です。
okamotoと一緒にRubyKaigi2022にオフラインで参加してきました!
Day2の後半について書いていきます。
今回も「私がRubyKaigi 2022に参加して感じたこと」、「私が参加したセッションで話されたことの要約と感想」を主に書きます。

Day1, Day2前半の記事をまだご覧になっていない方はこちらも是非御覧ください。
tech.enechange.co.jp tech.enechange.co.jp
Method-based JIT compilation by transpiling to Julia
要約
背景
純粋なRubyで大きな数字の配列を扱う場合、MJITやYJITが使えるようになった現在においても、あまり速くならない
これらのJITは「Rubyのセマンティクス = 動的なmethod dispatch」(以下スライド参照)を利用することが原因
しかし、Rubyのセマンティクスは数学的なアルゴリズムでは意味をなさないから、無視してしまった方が高速化できる
Cの拡張ライブラリを書き直すことなく、それを実現したい
コンセプト
- CPythonのJITであるNUMBAの
nopython modeのように、Rubyのコードから効率的にネイティブコードを生み出したい - Juliaがまさにその処理をできるので(以下スライド参照)、RubyをJuliaにトランスパイルしてしまえばいいじゃん
結果
- 非常に複雑なアルゴリズムがJuliaにコンパイルすることで高速化できた →大成功🎉
- 一方、配列の変換が大きなオーバーヘッドとなり、配列の変換が重いアルゴリズムはかえって遅くなってしまった
感想
- 「難しそうなことはJuliaにやらせよう」は笑ってしまいましたが、実に潔いアプローチだと思いました。
「Rubyの裾野を広げたい」 「データ解析の分野でも大好きなRubyを使いたい」
と日々努力してくださっているMurataさんを始めとした優秀なRubyistの皆さんには頭が下がる思いです私も微力ながらコミュニティに貢献していかねば・・!と決意を新たにしました
How fast really is Ruby 3.x?
Speaker: Fujimoto Seiji
Slide : RubyKaigi2022/20220908-RubyKaigi2022.pdf at master · fujimotos/RubyKaigi2022 · GitHub
要約
目的
- Ruby3x3*を現実のアプリであるFluentdから評価しよう
- YJITについてのフィードバックを求めるShopifyチームへのアンサー
* Ruby3をRuby2の3倍速くしようという計画のこと
Fluentdで計測する意義
FlutentdはRailsアプリよりも正しくRuby3x3を評価しうる
- 今までにもRuby3x3を評価する試みはあったが、多くはRailsアプリであった
- 実はRailsでは重たい処理はDBが担っているので、Ruby3x3でRailsの速度が3倍になることはない
- 一方で、Fluentdは1時間あたり何百万ものRubyオブジェクトを常時扱い続けることも珍しくない
- その点でFluentdはRailsアプリよりも正確にRuby3x3を評価しうる
Flutentdは息の長いプロジェクトなので、長期的にRubyのバージョンを比較できる
- Ruby1.9.3-Ruby2.7.6(一部OS向けに先行してRuby3.1.2)のパッケージがある
Ruby3x3は達成されたのか?
- 結論:
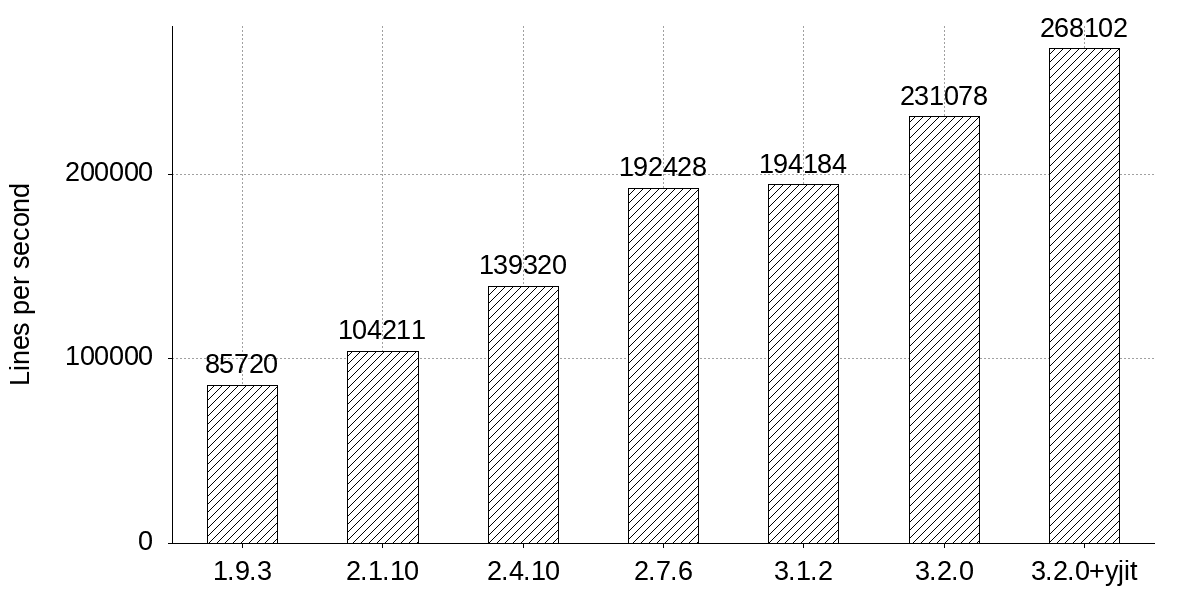
Fluentdにおいては概ね達成したと考えている(すごい・・🎉)- 検証方法:1000万行のLTSVの読込/パース処理のスループットをカウントした
- Ruby3.2は1.9の3倍(正確には3.15倍)のスループットを出すことができた
他言語との比較
- とは言え、他言語と比較するとまだまだ速いとは言えない
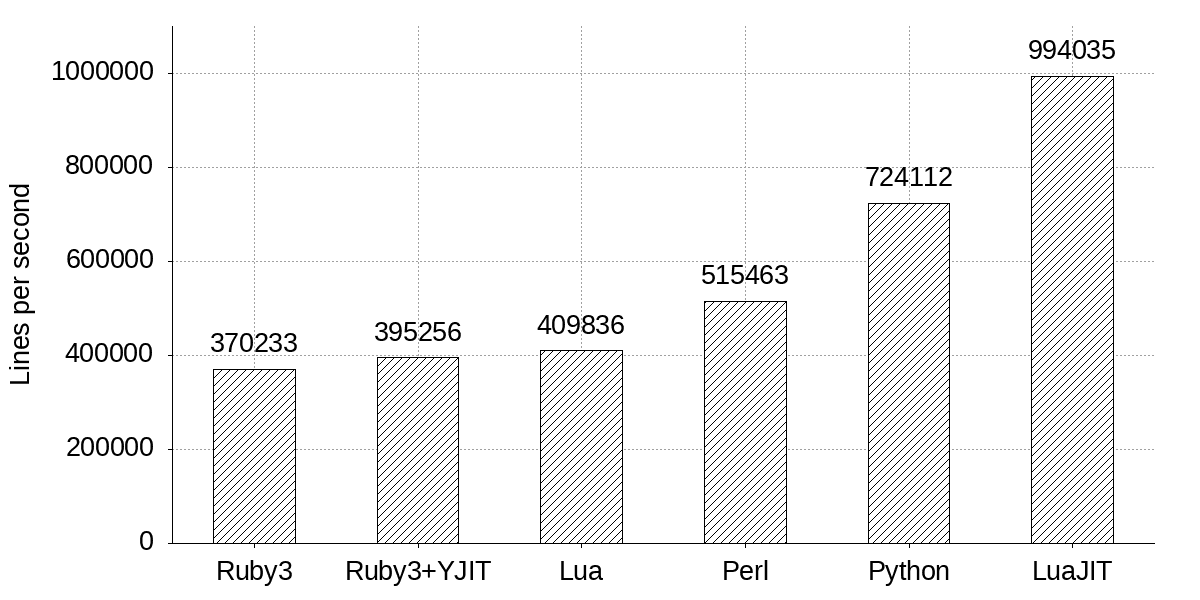
- ということで、"Ruby3x3 Revisited"*に期待!
* RubyKaigi 2021のMatzさんの講演で、Ruby 3.xはRuby3.0より3倍速くしようと宣言された
その他
- YJIT最高!
- FluentdにYJITサポートを有効化するオプションを追加し、約10%の速度向上を確認
- Ractor導入には課題あり
- Ractorを利用すると並列処理ができるという売りがある一方、オブジェクトの共有に制限がつく
- Fluentdのベースクラスにこの制限に引っかかる部分があるため、現状ではRactorは一切使えない・・😭
- Ractor活用のためにはエンジニアリングが必要なため、活用報告は来年以降になりそう
感想
- Ruby3x3を検証した事例を知らなかったので、とても興味深かったです
- Fluentdで検証することで、純粋にRubyとしてのパフォーマンスを計測でき、大変素晴らしいセッションでした
- 早くRailsアプリでYJITの恩恵を受けたいですが、この辺は運用実績の問題もあるので、もう少し様子を見たいところです
Packet analysis with mruby on Wireshark - dRuby as example
- Speaker:Misaki Shioi
- Slide: Packet analysis with mruby on Wireshark - dRuby as example - Speaker Deck
要約
前提知識
Wiresharkとは?:
広く使われているnetwork packet analyzernetwork packet analyzerとは?:
ネットワーク上のパケットフローを分析し、人間が読める形式で表示するソフトウェアWiresharkでprotocol dissectorとは?:
様々なプロトコルを分析するためのbuilt-in module
背景
- デフォルトでサポートされていないprotocolについては、dissectorを自作することができる
- 現在、dissectorを自作するためにWiresharkが提供するAPIはLuaとCにしか対応していない😭
チャレンジ
ShioiさんはWiresharkにmrubyをembedすることで、Rubyでdissectorを書けるようにした拡張Wiresharkを開発したそうです(←すごい!!!)
repository: https://github.com/shioimm/wireshark_with_mruby
Rubyでdissectorを開発する方法
dissectorでパケットを分析するためには、最低でも以下の2機能の実装が必要
- ヘッダーフィールドを含むプロトコルの情報を登録する
- 各データのパケット内の位置を、そのデータを分析するためのヘッダーフィールドに紐づける
Rubyでも上記の2機能を開発することが必要(以下スライド参照)
- Ruby dissectorはcofigファイルライクなDSLで書ける
- その他、Shioiさんが作成してくださった色々な便利機能が使える
mrubyで拡張Wiresharkを実装する方法
- Rubyでdissectorを開発するためには、以下の2つの振る舞いがWiresharkにbuilt-inされる必要がある
- WiresharkはRubyのコードを解釈できる必要がある
- Wiresharkが起動する際に、dissectorはconfigファイルをロードできる必要がある
dRuby packetを分析してみる
- 上記を踏まえて、dRubyのパケットを分析するRuby dissectorを作成した
→ 成功🎉(以下スライド参照)
感想
不勉強でそもそも「Wiresharkやdrubyって何?」という状態で聞いていましたが、非常に丁寧な資料だったのでスッと頭に入ってきました。
また、一見Rubyが使えないツールでもOSSであれば、十分に理解を深めることでRubyを使えるような拡張さえできるのだと、驚きました。
こういった高い視座で技術的なチャレンジをしていくShioiさんの姿勢を、私も是非見習っていきたいです!(ハードルは高い・・)
ちなみに本セッション中にネットワークトラブルが発生してセッションが一時中断したのですが、その間にShioiさんと参加者間で和気あいあいとしたコミュニケーションがあり、とても良い雰囲気でした!
(Twitterなどでは昔のRubyKaigiっぽくて良かったと好評でした😄)
Night Time
夜は他社から参加されたエンジニアの方との飲み会に参加しました。
(セッティングしてくれたokamotoさん、ありがとう!)
他の環境で頑張っているRubyエンジニアの話はとても刺激になりました。もっと頑張っていかないと・・💪
最後に。Rubyと津ぎょうざは最高です!
