ENECHANGE所属のエンジニア id:tetsushi_fukabori こと深堀です。
執筆時点で暦の上ではとっくに秋ですが厳しすぎる残暑が続いています。
それでもようやっと愛犬の夜の散歩では涼しさも感じられるようになってきました。
同僚の id:iwamot さんが作成したChatGPT Bot作の夜に散歩するバーニーズマウンテンドッグ画像を貼っておきます。ご査収ください。

ChatGPT Botによる画像生成はこちらの記事で紹介されています。
前回に引き続き弊社アプリケーションで発生したエラー事象とその調査について記事を書きます。
エラーが発生したアプリケーションはいわゆるwebアプリケーションなのですが、原因の調査手法としてはパケットキャプチャを行うことになりました。
普段webアプリケーションの開発ではあまり出番が無い(と思う)パケットキャプチャなので、方法などを共有できればと思います。
今回はキャプチャしたパケットの解析です。
この記事を届けたい人
- AWSで構築したアプリケーションでパケットキャプチャをやりたい人
- キャプチャしたパケットを解析した事例を知りたい人
事前準備
まずいきなりなんですが、termsharkの設定を変更します。
というのも本番アプリケーションは様々な通信をしているので、その中から特定のユーザーのPOSTに対応した外部APIサーバーとのやり取り(TCPコネクション)を何らかの方法で見つける必要があります。
この際、デフォルトの設定だとsrc/dstのIPアドレスは分かるのですが、ポート番号も知りたくなります。
アプリケーションがTCP通信を開始するとき、通信先(dst)のポート番号は明示的(またはプロトコルから暗黙的)に指定するかと思います。HTTPSなら443とかSSHなら22とかですね。
このときアプリケーションは自身(src)のポート番号を自動で割り振っていて、src/dstともにIPアドレスとポート番号のセットでやり取りをします。
通信先からの戻りのパケットはそのポート番号を指定して送られてくるので、アプリケーションは同じ2つのIPアドレス間の複数のTCPコネクションを見分ける事ができます。
今回もパケットを一覧で並べたときにポート番号で見分けられたほうが視認性が良いのでそのようにします。
termsharkを起動してESC押下→矢印キーで右上のMiscにカーソル移動してEnter→Edit Columnsに移動してEnterでカラム編集メニューを開きます。
出てきたメニューで以下のように設定すればポート番号が表示されます。


正常パターンの通信例
まず正常なリクエストのパターンを確認します。
termsharkでpcapファイルを開き、いくつかの手順でfilterを駆使して特定のセッション(アプリケーション的な意味。ユーザーのリクエスト受信〜レスポンス返信まで。)内のパケットを抜き出します。
一連の処理はユーザーのHTTPリクエストから始まるので、当該エンドポイントへのリクエスト(1)を検索します。
(1)のリクエストを受信したアプリケーションサーバのIPで、(1)の次に外部APIサーバーと行っている通信(2)を検索します。
(1)からユーザーのIP(内部的にはロードバランサの内部IP)とポートを、(2)からアプリケーションサーバのIPとポートを特定し、以下の条件でパケットをフィルタします。
(tcp.port == ユーザーポート and (ip.src == ユーザーIP or ip.dst == ユーザーIP)) or (tcp.port == アプリポート and (ip.src == アプリIP or ip.dst == アプリIP))
結果は以下のとおりです。
赤丸がアプリサーバーのIP、青丸が外部APIサーバーです。
黄色は通信内容の概略です。
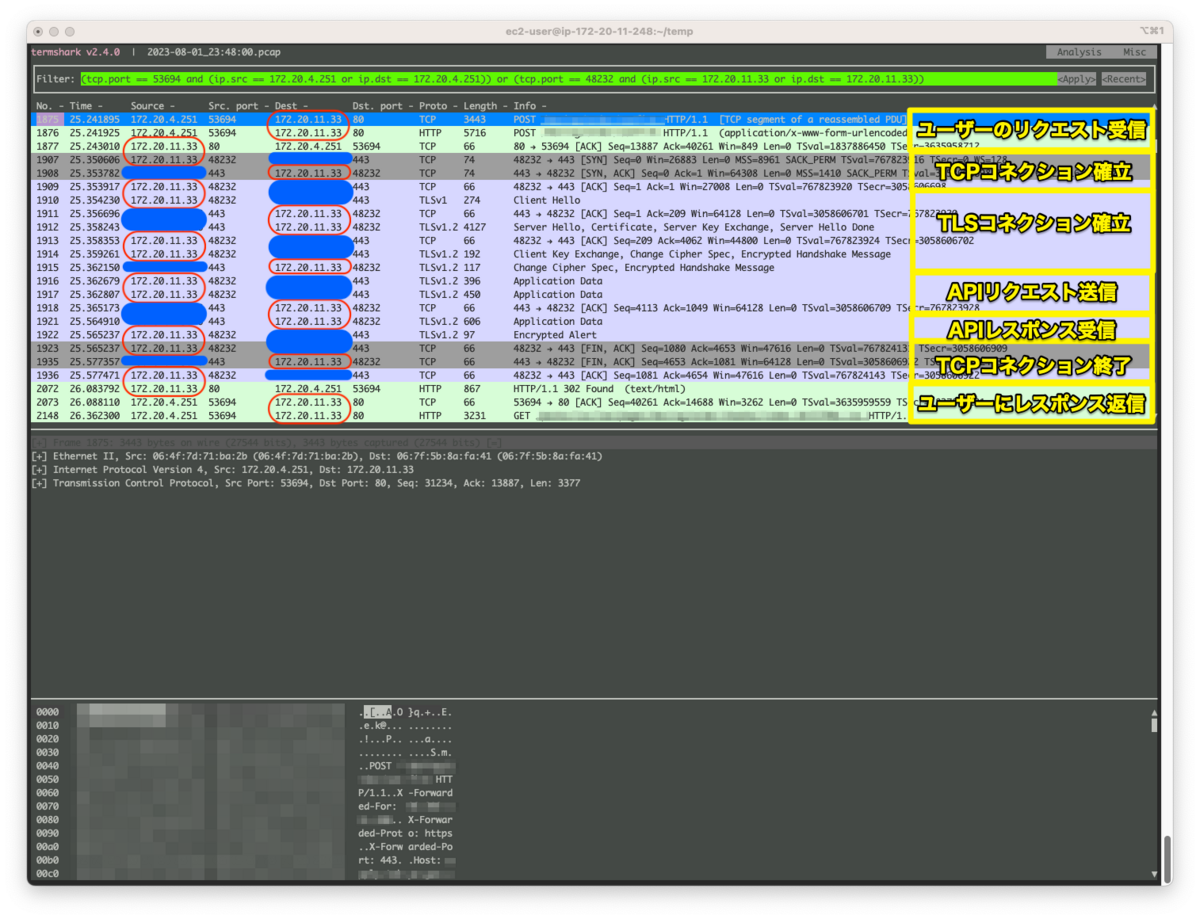
以下の流れを行っています。
(スペースがなかったので画像ではTLSコネクション終了を省略しています。「APIレスポンス受信」の最後の行が該当でTLS AlertによるClose-Notifyです。)
- リクエスト受信(ユーザー→アプリサーバー)
- TCPコネクション・TLSコネクション確立(アプリサーバー←→外部APIサーバー)
- APIリクエスト(アプリサーバー→外部APIサーバー)
- APIレスポンス(外部APIサーバー→アプリサーバー)
- TLSコネクション・TCPコネクション終了(アプリサーバー←→外部APIサーバー)
- レスポンス返信(アプリサーバー→ユーザー)
これが正常パターンです。
なお内部的にはDBサーバーへの通信なども間に行っていますが省略しています。
エラー検知・情報収集
次にエラーパターンです。
エラーパターンの検知はbugsnagによるエラー通知の発報から始まります。
bugsnagにきていた通知からは以下のような情報が得られました。
- エラー原因となったRubyの例外インスタンスのクラス:
Faraday::ConnectionFailed - 当該例外インスタンスの
#message:execution expired(エラーパターン1) またはConnection reset by peer(エラーパターン2) - AWSがALBでユーザーリクエストに挿入した
X-Amzn-Trace-Idヘッダの値:Root=1-64c91da2-42b1d28869bd00ce62383d52など - エラー発生のタイムライン
上2つはエラーそのものの情報なのでパケットの解析には特に使いません。
下2つはパケットを見つける上で必要な情報です。
X-Amzn-Trace-IdヘッダはALBが挿入するヘッダでリクエストをトレースするための識別子として使用できます。
termsharkでもユーザーのリクエストのパケットをまず最初に見つける必要があるので上記X-Amzn-Trace-Idヘッダの値を使用することで対応します。
エラー発生のタイムラインは確認対象のpcapファイルを特定するために使います。
今回のエラーはユーザーのリクエスト受信から30〜60秒経ってから発報するため、パケットはその時間内に散在しています。
このため確認する対象のpcapファイルもエラーのタイムラインの時間帯を包含するもの(場合によっては複数)を選びます。
また見つけたパケットが当該エラーのものかどうかを見分けるためにも使います。
エラーの発報時刻はリクエストの発生から時間が経っているため、ユーザーのリクエスト時刻などの情報でセッション内のパケットの時刻が一致するか確認します。
エラーに対応するコネクションの発見
まずエラーの時刻からpcapファイルを特定します。
ユーザーのリクエスト時刻よりも前の最後の日時がファイル名に含まれるpcapファイルから、エラー発生時刻よりも前の最後の日時がファイル名に含まれるpcapファイルが対象です。
(tcpdumpのローテーションはそのファイルに書き込み開始した時刻がファイル名となるため)
当該のpcapファイルを開きX-Amzn-Trace-Idヘッダでフィルタリングします。
http and http.request.line contains "Root=1-64c91da2-42b1d28869bd00ce62383d52"
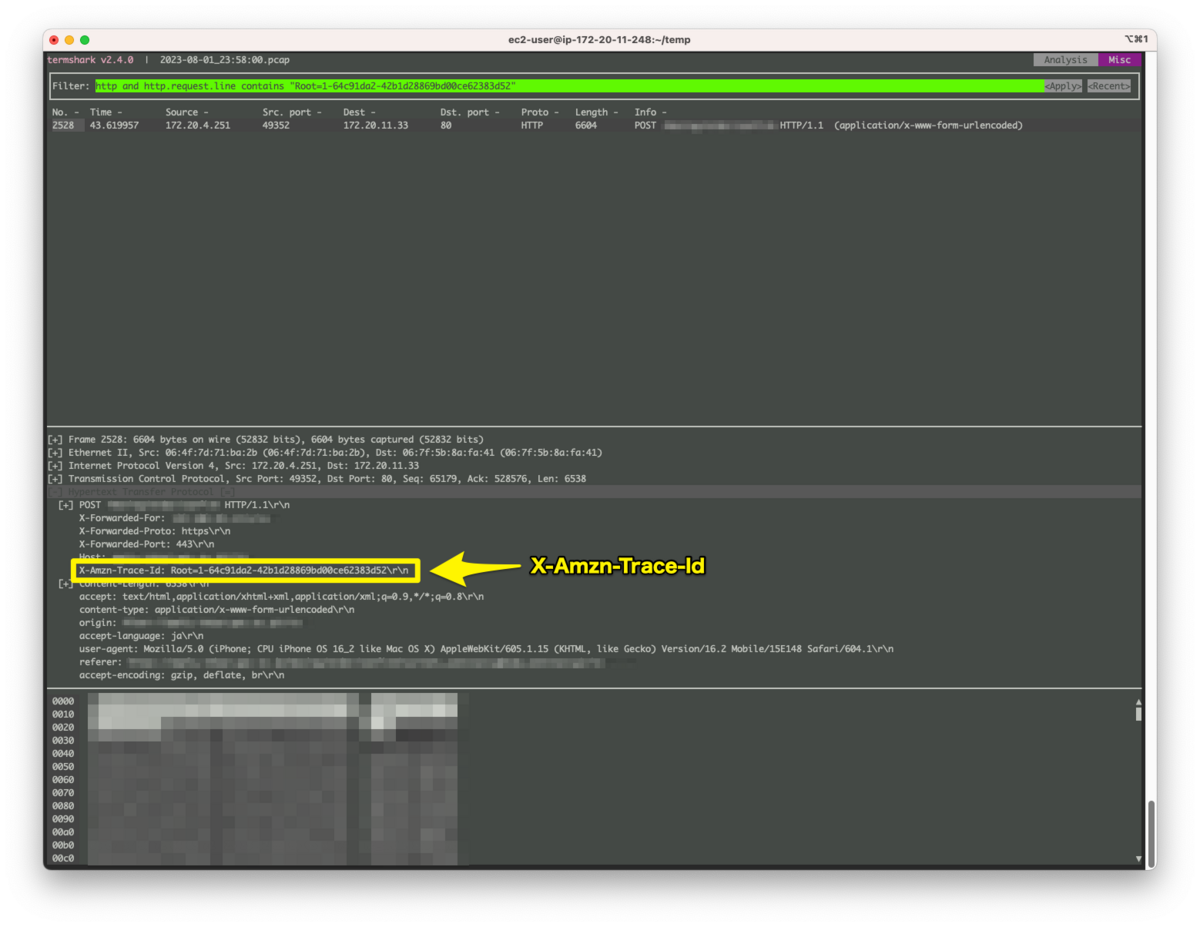
HTTPヘッダのX-Amzn-Trace-Idヘッダで個別に検索ができなかったのでリクエスト全体から文字列検索しています。
一般的なヘッダであれば == で検索できます。
ユーザーIPとポート(172.20.4.251:49352)がわかったので控えておきます。
また、リクエストを受け取ったアプリケーションサーバーのIPがわかりましたので、今度はこれで検索します。
ip.src == アプリサーバーIP or ip.dst == アプリサーバーIP
上記のリクエストがNo.2528とわかっているので、これの後の位置まで移動します(Packet List Viewを選択中に2528Gでジャンプできます)。
しばらくDBとサーバとの通信が続いた後、外部APIサーバーとの通信が見つかります。
今度はアプリサーバーのIPとポート(172.20.11.33:41198)を控えておきます。
最後に以下のようにフィルターを設定して全通信を見つけ出します。
(tcp.port == 49352 and (ip.src == 172.20.4.251 or ip.dst == 172.20.4.251)) or (tcp.port == 41198 and (ip.src == 172.20.11.33 or ip.dst == 172.20.11.33))
見つけたパケットの内容を見ていきます。
エラーパターン1の原因究明:TCPコネクション確立の失敗
エラーパターン1のパケットは以下の通りでした。
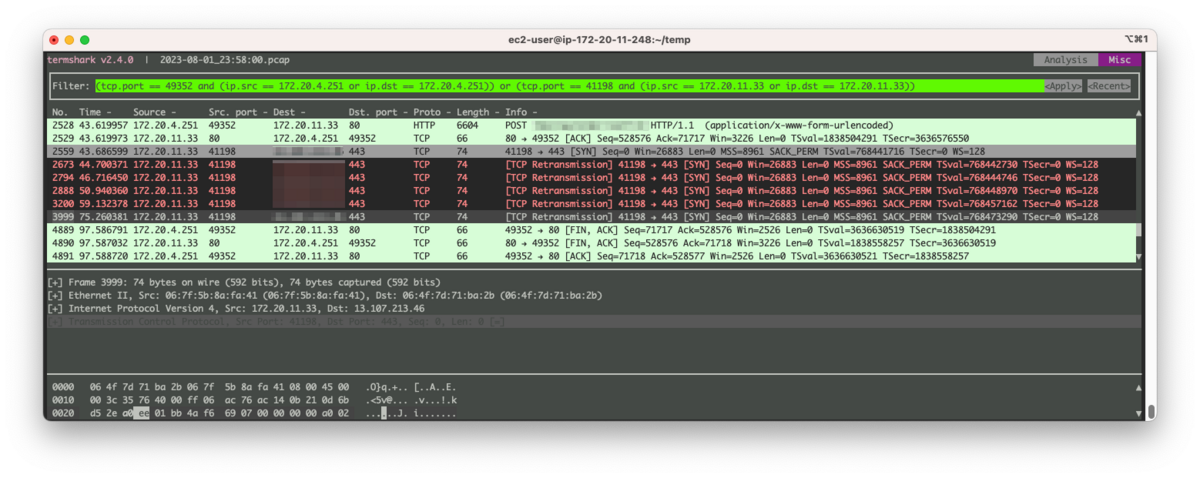
見ていただけると分かるのですが正常パターンとは明らかに異なっています。
よく見ると通信はアプリケーションサーバー→外部APIサーバーの方向、しかも一番最初のSYNと書いているものしか発生していません。
このSYNと書かれているパケットはTCPの3ウェイ・ハンドシェイクにおけるコネクション開始のSYNビットが立ったパケットです。
正常パターンではこのパケットに対して外部APIサーバーからSYN, ACKのビットが設定されたパケットが返って来ているのですが、今回はそれが見当たりません。
その後TCPの再送制御として1秒後、2秒後、4秒後…とバックオフ時間を広げながらSYNパケットの再送を行っています。
その後、アプリケーションサーバーで稼働しているnet-httpライブラリのopent_timeout時間である60秒に到達し、エラーとなっています。
エラーパターン2の原因究明:RSTによるTCPコネクションの強制終了
同じくエラー通知から見つけたRoot=1-64d1bcdf-703478be62e18301776edba6を元に通信を抜き出します。

こちらはやや分かりにくいですが、正常パターンと見比べると「APIレスポンスを受信」が発生せず、RSTフラグが設定されたパケットが返ってきていることがわかります。
RSTはTCPコネクションの中断を起こすフラグです。
RST受信前に外部APIサーバからパケットを受信していますが、これはAPIリクエストに対する到着連絡のACKです。
正常パターンではACKの後すぐにAPIレスポンスデータが到来しますが、エラーパターン2では約15秒ほど間をおいてRSTが到着します。
考察とその後の原因究明
以上から、エラーにおいては下記のいずれかの状態が発生していることがわかりました。
- TCPコネクション確立時の
SYNに対するACKが外部APIサーバーから返ってこない - 外部APIサーバーへリクエスト送信後にレスポンスが返ってこず
RSTが返ってくる
これらはアプリケーションサーバーから見るといずれも外部APIサーバーから無視または拒絶されているように見えます。
もちろんNWの問題による通信断(に伴うSYN, ACKなし)や、一定以上時間が経過したことによる外部APIサーバーのタイムアウト(に伴うRST送信)などが有り得ますが、アプリケーションサーバー側からはこれ以上は探れなさそうです。
しかし同時間帯に同一IPの外部APIサーバーとTCPコネクションが確立できているセッションがある、TLS通信が開始できているので外部APIサーバーのTLS終端(ロードバランサなど)と通信できている…などの状況もわかっています。
これらを元に外部APIサーバーに対して調査を依頼することが次のアクションになるでしょう。
まとめ
AWS上に構築されたアプリケーションで発生した外部APIサーバーとの通信に起因するエラーに対してパケットキャプチャ環境を構築して解析を行いました。
パケットレベルで解析することで「どこまでが上手くいっていて」「どこが上手くいっていないか」を詳細に手に入れることができました。
このようにAWS上の本番環境では、本番環境側に影響を与えずアプリチームに対応をしてもらうことなくパケットキャプチャを行う事ができます。
パケットの解析自体もさほど難しくはないので、これから試してみようという方の参考になればと思います。
調査の進展が有りましたら続編が書けるかもしれません。