ENECHANGE所属のエンジニア id:tetsushi_fukabori こと深堀です。
記事を書くのが年単位ぶりなので書き方も忘れていました。そうか文章ってこう書くんだったねって感じです。
年初から取り組んだ内容は久しぶりに技術ブログで共有すると価値がありそうだったので書くことにします。
相変わらず開発環境のコストをどうにか下げられないか、という話題です。
今回は2025年3-4月に実施した開発環境のインフラ構成変更と、それによるコスト削減を紹介します。
タイトルの通りALBをなんやかやしてコストを削減します。
サーバーが必要なWEBサービスを公開するとどうしてもどこかにロードバランサーを置くことになり、結果的に居るだけでかかるコストが積み上がっていきますよね。
本番環境ならともかく、開発環境ではどうにかこのコストを下げたいものです。
今回はALBを複数のプロダクト・環境で共用することでコスト削減を図りました。
この記事を届けたい人
- 開発環境のコスト削減を考えている
- AWS VPCのNW構成を模索している
- CloudFront VPCオリジンを活用してALBのパブリックIPv4コストを減らしたい
背景
コスト削減
弊社に限らない話だとは思いますが事業には常にコスト削減が求められるものです。
もはや慣れたとはいえ140円台から戻ってこない為替もシステムのコストを増やす要因で、どうにかAWSのコストを減らしたいのはどこも同じかと思います。
加えて弊社はサービスの数が多く、様々なtoB/toCプロダクトがあります。
様々なプロダクトがあるということはその数だけ本番環境があり、本番環境の数だけ検証環境や開発環境があるものです。
そうするとやはり、「居るだけでコストがかかるリソース」の数も増えてきますしコストも嵩むものです。
これらをなんとかしたい、というモチベーションがありました。
AWSアカウント分割
加えて、弊社ではもともと少数のアカウントに多くのプロダクト・環境が同居していたのですが、ベストプラクティスに則ったアカウント分割を推進しています。
これに伴い本番系のアカウントと開発系のアカウントが発生したわけですが、もともと本番と同居していた開発環境はアカウントの引っ越しが必要になります。
つまり、このタイミングで「どうせ環境の構築と移行が必要」だったわけです。
こうしたタイミングであれば比較的「新しいシステム構成」も試しやすいです。
どうせ新規環境の検証は必要だし、うまく動かなければ既存環境と同じ構成にしてしまえばそれが正解だとわかっているのでやりやすい…というわけですね。
これを幸いとして、コスト削減のための構成変更も同時にやってしまおう、というのが今回の経緯です。
移行前の構成
NW構成
おおよそ以下のようなNW構成です。
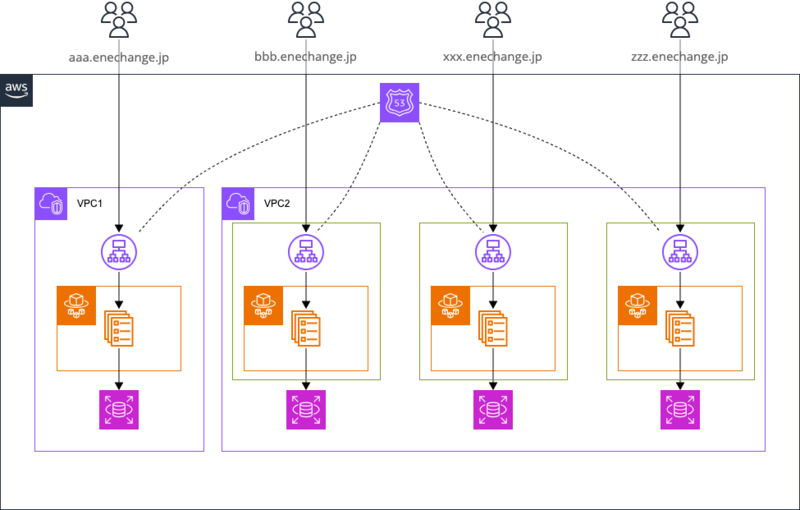
おおよそプロダクト毎にVPCが分割され、その中で環境(本番・開発など)毎にサブネットが分割され、サブネット内でアプリケーションのセット(ALB・ECS・NAT GW・RDSなどなど)が構築されています。
セキュリティ要件や歴史的経緯によって異なることもあります。
また、今回は開発環境にフォーカスを当てていますが、弊社の開発環境は大抵の場合ALBのセキュリティグループでIPによるアクセス制限を実装しています。
弊社のVPNや許可されたビジネスパートナー・顧客が所有するIPのみからリクエストを許可しています。
コスト構造
記事タイトルに示したとおりですが、ALBのコストが嵩みます。
ALBは台数x時間で発生するコストがあるため、台数が多くなる本構成ではどうしてもコスト圧力が高いです。
ALBは関連付けられるサブネットがAZから一つずつなので、サブネットやVPCが分割されている以上その数分のALBを立てざるを得ません。
また、VPCが分割されていることでインターフェイス型のVPCエンドポイントも数が嵩みます。
インターフェイス型VPCエンドポイントは個数x時間で発生するコストがあるため、こちらも個数は極力減らしたいです。
VPC内でエンドポイントを共用することはできますが、VPCが分割されているとそれぞれ設置せざるを得ません。
NAT GWも同じように時間コストが発生しますが、こちらは過去に集約しています。
今回のコスト効果の計測スコープ外ですが、こちらもいずれ開発環境分をアカウント移行することになるでしょう。
課題
もちろんコストです。
基本的にはNWが分割されているのはセキュリティ上良いと理解していますが、ことコストとなると上述の通り時間コストが発生するコンポーネントが増えることでコスト負担が大きくなります。
加えてコスト面ではECSをFargateで稼働している点もチリツモですがコストインパクトがありそうです。
先行研究では20%ほどのコスト減が見込めそうなので、こちらも今回はテストしてみます。
またセキュリティ的な観点でも - ALBがinternet facingで攻撃を受けやすい - WAFが導入されていないので攻撃への防御が弱い
などやや防御が手薄な環境が多そうです。
移行後の構成
NW構成
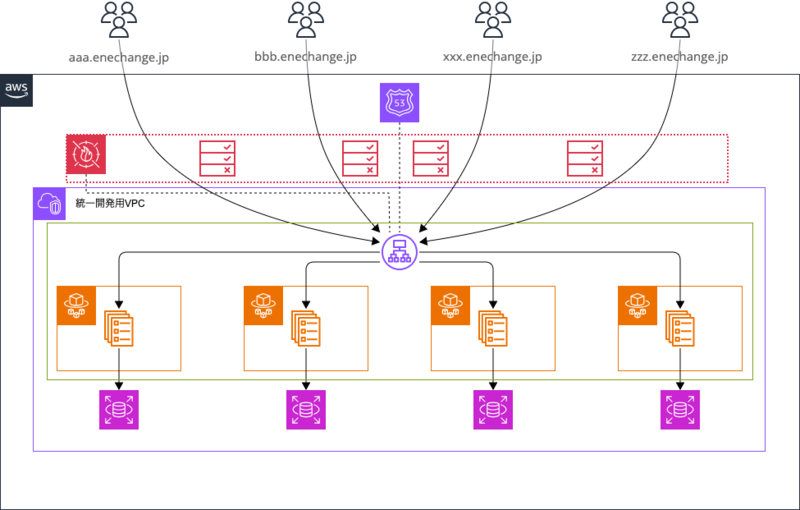
以下のようなNW構成にします。

- VPCは共用の一つだけを作成します
- パブリックサブネットは共用のものを複数AZ分作成します
- プライベートサブネットは共用のものを複数AZ分作成しますが、個々のプロダクト・環境のものを作成しても構わないです
- インターフェイス型のVPCエンドポイントは共用のプライベートサブネットに関連付けし、セキュリティグループでVPCのCIDR全体からのアクセスを許可します
- ALBは全プロダクト・全環境共用のものを一つだけ作成し、共用パブリックサブネットに紐づけます
- ALBはinternalとします
- ALBに80番ポートのリスナーを用意し、リスナールールとしてホストヘッダでリクエスト先のターゲットグループ(=環境)を設定します。リスナールールは最大100個まで設定できます。デフォルトのルールは404を固定レスポンスで返します。
- CloudFront Distributionをドメイン毎(≒環境毎)に作成しオリジンをCloudFront VPCオリジンにします
- CloudFront VPCオリジンを作成し、共用のVPCにENIを伸ばして通信可能にします
- ALBのセキュリティグループでCloudFrontのマネージドプレフィックスリストからのアクセスのみを許可します
- CloudFrontにはWAFを関連付けしてIP制限を実装します
- ECSやRDSといったアプリ固有のリソースは移行前と同様に構築します
- ECSはFargateではなくEC2で稼働させます
制約
今回の対応で発生した制約は「デプロイ方式としてCodeDeployによるB/Gデプロイが使えない」です。
なぜかと言うと、CodeDeployによるB/GデプロイはALBのリスナー(ルール)を操作してターゲットを切り替えるためです。
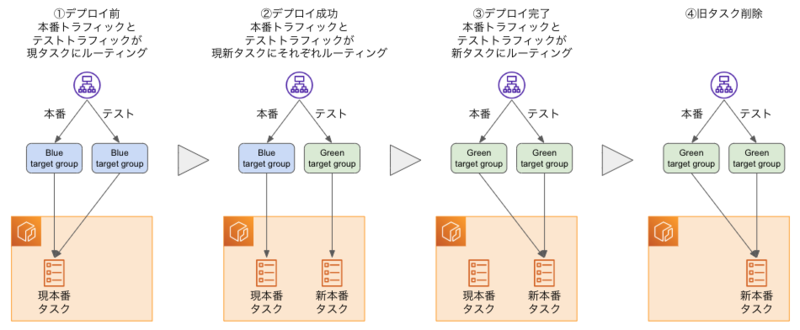
上図のような振る舞いは本番・テストそれぞれのポートに対応したリスナーの宛先になるターゲットグループをCodeDeployが操作することで実現しています。
つまり前提として本番・テストそれぞれのポートはCodeDeployが想定する形式のリスナールールが設定されている必要があり、今回のような特殊な構成は考慮されていないでしょう。
ALB共用によるコスト削減
理屈上どのようなコスト削減が起きるかを考えます。
理想的にはもともと環境数分存在していたALBが一つに集約されるので、移行対象の環境数 - 1台分だけALBの時間コストが減ります。
これが今回の共用LB化において最もコスト削減を期待するポイントです。
また、ALBをinternalにすることでALBのAZ分付与されていたパブリックIPv4のコストも移行対象の環境数 x AZ数分だけ削減できるはずです。
加えて、インターフェイス型VPCエンドポイントが集約可能になるので、移行対象環境のインターフェイス型VPCエンドポイント数 - ユニークなインターフェイス型VPCエンドポイント数分だけコストが減るでしょう。
一方でCloudFrontとWAFは追加となるコンポーネントなのでこちらはコスト増になります。
ただ、CloudFrontのデータ転送コストはALBのデータ転送コストと同じ(データ量が増えればより安い)設定になっており、かつ月間1TBの無料枠があります。
また、ALB to CloudFrontのデータ転送コストは無料なため、実質的にALBだけだった構成よりも無料枠分コストが下がります。
他にリクエスト件数ベースやオリジン向けのデータ転送量ベースのコストがありますのでこちらは影響を考えないといけません。
WAFはWeb ACLとルールでそれぞれ$5/月、$1/月の定額の時間コストがかかります。
今回の構成ではドメインごとに上記の両方のコストが掛かるため、他のコスト削減によってドメイン毎に$6/月以上の削減ができていないと赤字になります。
ECS on EC2の試験導入
ECSのコストは基本的にはキャパシティベースでの課金のため、同等のキャパシティのEC2インスタンスをインフラにすることでキャパシティあたりのコストの差額がそのまま減るはずです。
一方でEC2インスタンスをインフラとすることでAMIの管理やEC2インスタンスの管理など、運用コストの上昇が見込まれます。
このコストが許容可能かは運用しているチームにしか判断ができないかと思いますので、しばらく検証期間をおいて判断してもらうことにします。
とはいえ、AMIにはECS最適化されたAWSが提供するAMIがあり、こちらの最新版を利用する設定で特に困らないかな…というのが正直なところです。
今回の対応では後述する通りterraform moduleとして環境構築を提供しており、terraformで以下のように指定したAMIを起動テンプレートで利用することでapply時点での最新のECS最適化AMIを使うようにできます。
resource "aws_launch_template" "ecs_container_instance" { ... image_id = "ami-0b62cd163f837e749" # amzn2-ami-ecs-hvm-2.0.20230906-arm64-ebs ... }
ECS最適化AMIではECSエージェントも含まれているため何も考えずECSのインフラとして利用できました。
コスト構造
時間コストがALB一台に削減されます。
併せてインターフェイス型VPCエンドポイントやパブリックIPv4のコストも環境数に依存しないコストになります。
また新たな時間コストとしてWAFのコストが環境数に比例して計上されます。
キャパシティに依存するコストはFargateをEC2に変更することで削減が期待できます。
他のキャパシティ依存のコスト(RDSなど)は変更がありません。
データ量に依存するコストはデータ転送量が移行前後で変化しないため基本的には変わりません。
ただしインターネットからリクエストを受ける箇所がALBからCloudFrontに変わったことによりCloudFrontの無料枠分のコスト削減が見込めます。
一方でリクエスト数に応じたコストの増大は確認が必要です。
移行前課題の解決状況
「居るだけでコストが発生するコンポーネント」が削減され、コスト課題の解消が期待できます。
また、セキュリティ的にもWAFが導入されたことやALBがinternalになったこと、CloudFrontが入ったことによりDoSふくむ攻撃への耐性が向上しています。
移行後構成の工夫
デプロイ戦略の変更
前述した通り、今回の構成ではデプロイ戦略に制約があり、CodeDeployをデプロイコントローラーとしたB/Gデプロイが使えません。
今回の構成ではALBのリスナールールが特殊な構成になるからです。
このため今回移行した環境ではデプロイコントローラーをECSにし、デプロイ戦略としてローリングアップデートを採用しています。
デプロイ戦略としてのB/Gとローリングアップデートの違いは色々と語られているかと思いますので割愛しますが、開発環境なのでどちらでも良いのが正直なところかと思います。
ただしCodeDeployのようにデプロイ推移を見やすく表示してくれるわけではないので、慣れは必要です。
CloudFrontによるドメイン分割
もともとはALBをインターネット向けにし、複数のドメインと複数の証明書をALBに関連付ける想定でした。
ただこの方式だとWAFのルールが複雑になります。
もちろんできるのですが、「このドメインはこのIPを許可する」を全てのドメインに対してチェックするとラベルを付けて最後に許可してデフォルトルールを不許可にして…とややルールが大きくなりがちです。
また、terraformのリソース管理の都合上dynamicブロックの多用やdepends_onの考慮など複雑な実装になりやすかったです。
一方で別の観点として、私が所属するCTO室では開発チームにベストプラクティスを展開する、というミッションがあります。
この観点でwebアプリへのCloudFront導入を推進する目標がありましたが、なかなか進んでいないのが現状でした。
そこで今回、上記のALBの問題の解消方法としてCloudFrontの導入を必須にし、CloudFrontでドメインを分割する方式にすることでCloudFront導入の推進も行うことにしました。
CloudFront Distributionをドメイン毎にたてることにより以下のメリットがあります。 - CloudFrontに関連付けたWAFでそのドメインに関するIP制限だけを実現すれば良く、WAFのルールで複数ドメインを考慮する必要がなくなる - CloudFront VPCオリジンを利用することでオリジンとなるALBをinternalにできるので攻撃耐性の向上やIPv4コストの削減ができる - TLS終端をCloudFrontに任せることで証明書はドメイン毎に一つ考えれば良く、ALBに複数の証明書を付与する必要がなくなる
terraformモジュール化
本環境を用意に構築できるよう、CTO室製のterraform moduleとして社内に公開しました。
移行前の環境もそうですが、弊社ではインフラ構成をterraformで管理しているので、よいプラクティスが見つかったらモジュールにして展開するカルチャーがあります。
今回のモジュールは共用部分とそれ以外とで2つのモジュールに分割しました。
| 項目 | 共通モジュール | 環境モジュール |
|---|---|---|
| 主なリソース | ALB CloudFront VPCオリジ |
ALBリスナールール WAF ECSサービス |
| 使用する単位 | ALB毎 | 環境(=ドメイン)毎 |
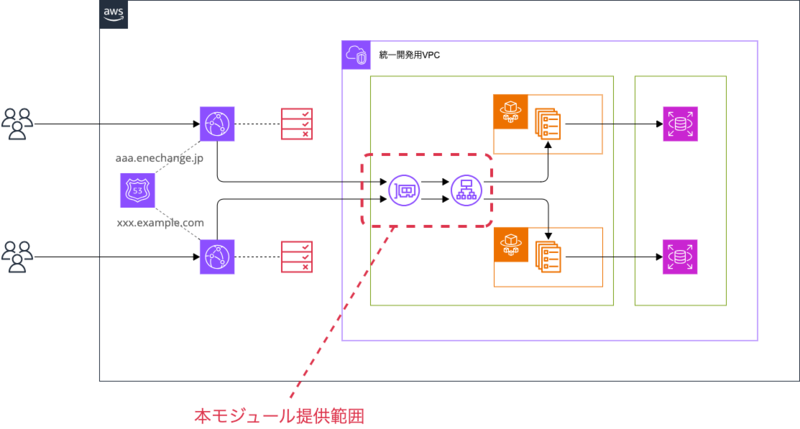

NW構成とCloudFront Distributionはモジュール外としています。
これはどちらもアプリ要件を吸収する必要があるためで、例えばCloudFrontのキャッシュ戦略などはモジュールに含まれてしまうとカスタマイズが困難になります。
コスト削減効果検証
計測方法
以下の方法で移行前/移行後のコストを計測・比較します。
- 試験的に移行した3環境について並行稼働期間の1週間を対象にコストを比較します
- 移行前/移行後はそれぞれAWSアカウントが異なるため、それぞれのアカウントのCost Explorerからコストを取得します
- 弊社では環境を識別するコスト配分タグとアプリケーションを識別するコスト配分タグが設定されているので、これらを指定して移行対象の環境および共用LBコンポーネントのコストを取得します
- 取得するコストは使用タイプで集計し、期間中の総コストにおける割合が1%以上の使用タイプのみを比較対象とします
- 使用タイプ毎に全てのコストを机上計算し検算します
- 何らかの理由でコストに含まれていない・または不要なコストが含まれている場合は手計算にてその分のコストを算出し加算または減算します
なお、AWSアカウントの分離に伴い移行元と移行先はどちらも同一組織に含まれていたので組織の管理アカウントでどちらのコストも取得できて楽でした。
全体で42%のコスト削減達成!!!
結論はタイトルのとおりです。
🎉🎉🎉計測期間のコストで42%削減を達成しました〜〜〜🎉🎉🎉
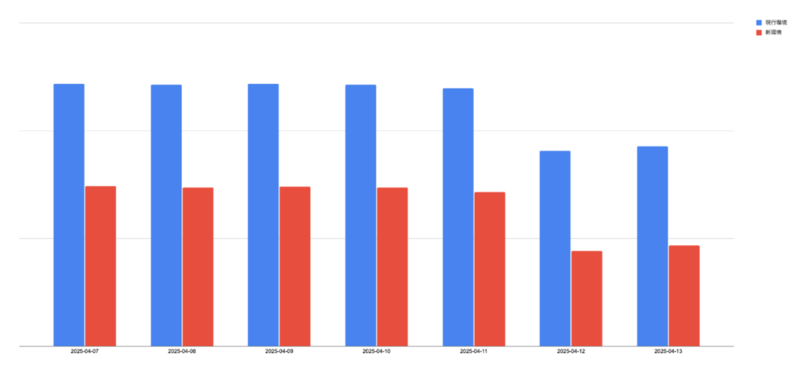
日によって総コストの大小があるのは土日にインスタンスを落としているからです。開発環境なので。
机上でコストが減らせそうだというのはわかっていましたが、4割減という比較的大きなコスト削減ができることが分かったは良かったです。
非本番のコストがこれだけ圧縮できたら嬉しいですね。
以降ではコスト削減に何がどの程度寄与したかを確認します。
NW構成の変更によるコスト削減効果
NW構成(ALBの共用やIPv4の削減、CloudFrontの導入など)によると、同時に行ったECS on EC2の効果を使用タイプで切り分けて確認します。
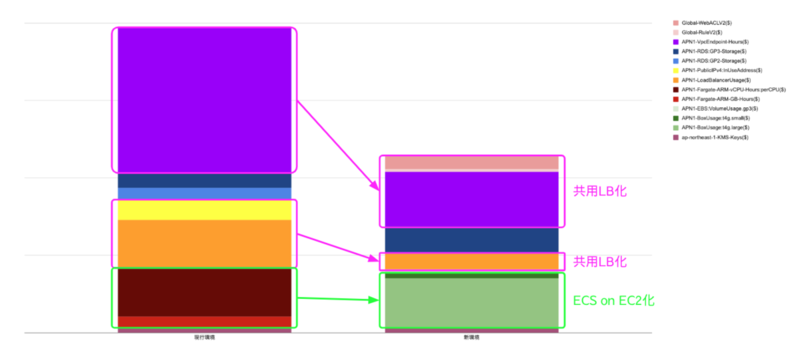
まず一番上の紫の部分の使用タイプはAPN1-VpcEndpoint-Hoursです。VPCが集約されることでエンドポイントが削減されたことが大きく寄与しています。
次に黄色とオレンジはそれぞれAPN1-PublicIPv4:InUseAddressとAPN1-LoadBalancerUsageです。ALBがinternalになったことでパブリックIPv4コストがなくなり、またALBの台数が減ったことで時間コストが削減されています。
一方でNW構成変更によって増えたコストもあります。
移行先(新環境)のグラフの一番上の方のピンクに近い色はGlobal-RuleV2とGlobal-WebACLV2です。新たにWAFでIP制限を実装することでコストが増加しました。
NW構成変更によって発生した使用タイプ毎のコストの増減率は以下のとおりです。
| 使用タイプ | 削減率 |
|---|---|
APN1-VpcEndpoint-Hours |
62.5 % |
APN1-LoadBalancerUsage |
66.7 % |
APN1-PublicIPv4:InUseAddress |
100.0 % |
Global-RuleV2 |
- % |
Global-WebACLV2 |
- % |
| 計 | 59.2 % |
使用タイプ毎の金額の絶対値には大小があるのですが、上記の表は削減額の絶対値の大きい順で上から表記しています。
絶対値的にはあまり意識していなかったインターフェイス型VPCエンドポイントのコスト削減額が一番大きくなりました。
嬉しい驚きですが、同時に無意識にコストを食うコンポーネントがそれなりの数・金額居たということですので、もっとコスト意識を高めていくべきだなとも思いました。
一方で、ECS on EC2についてはグラフからも分かる通り、ほとんどコストが削減されていません。
2割程度のコスト削減を見込んでいたのでこれはネガティブな驚きです。
使用タイプの内訳は、移行元(現行環境)の赤っぽい部分がAPN1-Fargate-ARM-vCPU-Hours:perCPUとAPN1-Fargate-ARM-GB-Hoursです。予想通りほとんどFargateのコストです。
移行先(新環境)ではそれに相当するAPN1-BoxUsage:t4g.largeとAPN1-BoxUsage:t4g.smallが計上されました。なお後者については無料枠の範囲内なので単純に取得したコストには載っていませんでしたが手計算にて追加しています。
また少額ですがAPN1-EBS:VolumeUsage.gp3も計上されていました。
これらのコストの総額での削減率は3.6 %でした。(使用タイプが移行前後で完全に異なるので使用タイプ毎の比較は無意味になるため省略します。)
これはほぼ効果がないと言っていいですね…どうしてでしょうか?
ECS on EC2のコスト改善
ECS on EC2のコスト削減がほとんど効果がなかった理由は実は構築時点から自明でした。

ご覧の通り、EC2インスタンスはFargateに比べて倍のメモリキャパシティを指定しています。
つまり、アプリが求めるメモリ量(=Fargateで稼働しているタスク定義のメモリ量)よりもECSのインフラとして使用するEC2インスタンスのメモリ量が倍用意されている状態になっているわけです。
EC2インスタンスのコストはキャパシティに比例する倍々ゲームなので、メモリ量の観点だけ見るとアプリで必要とする倍のキャパシティ、倍のコストを払っていることになります。
当然コスト効率が悪くなりますが、なぜこうなるのでしょうか?
答えは実はすでに本文中に記載しているのですが、ECS on EC2においてECSタスクはEC2インスタンスの全てのキャパシティは利用できず、ECSエージェントの使用分を差し引いた分が使えるキャパシティになります。
具体的にはメモリのうち200~400MiBはECSエージェントが使用していました。
このため、アプリの要求メモリ量がEC2インスタンスのインスタンスタイプで定義されているメモリ量と同量だと、一つ大きなインスタンスタイプが必要になりまし、EC2インスタンスのメモリの半分弱は余った使われないメモリになります。

このままであれば流石に、Fargateのママのほうが管理コストも考えてお得に見えます。
ところでFargateではおおよそ1GiB単位でタスク定義にメモリ量を指定できます。
一方EC2においてはMiB単位で任意のメモリ量をタスク定義に指定することが可能です。
つまりメモリ量の自由度はEC2の方がはるかに高いわけです。
ここで気になるのはアプリが実際にどの程度メモリを使用しているか、です。
そこで移行対象環境のうち一つについて、半年間の期間でどの程度メモリを使用しているかを確認しました。
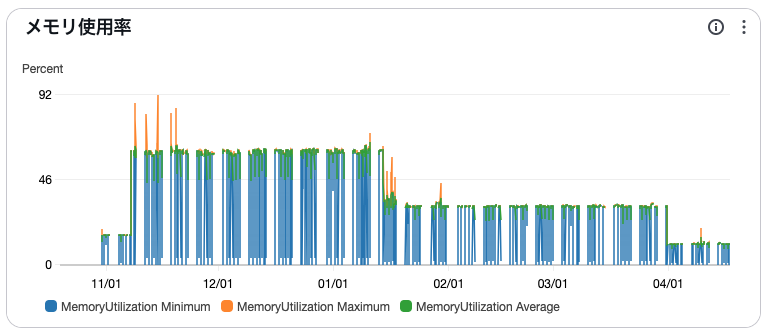
グラフの期間において途中でメモリ量が増やされているため率だとわかりにくいですが、現在のFargateのタスク定義のメモリ量と比較するとメモリがあまり気味に見えます。
EC2を使う際、このメモリの余剰を適切にコントロールすればインスタンスタイプを小さくし、コスト削減ができる可能性が高そうです。
ただしFargateのオンデマンド料金とEC2のオンデマンド料金はコストのモデルが違います。
FargateはvCPUとメモリ量それぞれでコストが計算されるのに対しEC2はvCPUとメモリ量がインスタンスタイプという形でセットになってコストが計算されるため、その上で稼働するアプリケーションの性質(CPUバウンド/メモリバウンド、許容できる性能など)によってどちらがコストで有利か、どの程度有利かは流動的でしょう。
Tips
やっていて気がついた・感じたTipsを残しておきます。どなたかのお役に立てれば嬉しいです。
ALBリスナールールのterraform管理
今回ALBのリスナールールを複数管理するに当たり、その優先順位をどうするかが少し悩ましかったです。
というのもリスナールール自体はそれぞれ別の環境に対応しているので優劣はないのですが、優先順位を手動で指定する必要があるとすると「いま利用可能な優先順位」を認識していないといけなくなります。
(優先順位は同値禁止です)
terraformのAWSプロバイダーのドキュメントを確認すると優先順位について以下の記載がありました。
priority - (Optional) The priority for the rule between
1and50000. Leaving it unset will automatically set the rule with next available priority after currently existing highest rule. A listener can't have multiple rules with the same priority.
文章からは「最優先のルール」なのか「最大優先順位のルール」なのかはわかりませんが、AWSプロバイダーのソースコードを見る限り最大優先順位のようです。
つまり最大の優先順位が10なら11として新たなルールを追加してくれる、ということですね。
これであれば既存の優先順位を気にすることなくモジュールでルールを追加していけます。
CloudFrontの無料枠
CloudFrontの無料枠は大きいです。2025/04時点で以下のようになっています。
| 料金コンポーネント | 無料枠 |
|---|---|
| インターネットへのリージョンレベルのデータ転送 (OUT) | 最初の 1TB |
| HTTP メソッドのリクエスト料金 | 最初の 1,000 万件の HTTP (S) リクエスト |
| オリジンへのリージョンレベルのデータ転送 (OUT) | なし |
弊社の数ある開発環境を調べましたが、いずれの無料枠も開発環境100個ぶん以上です。
開発環境で使う分には無料枠の中に何個も環境を立ち上げられそうです。
CloudFront VPCオリジンをterraformで扱う際の制約
CloudFront VPCオリジンを使うとオリジンをVPCのプライベートリソースにできます。
つまりインターネット向けALBではなくinternal ALBをオリジンにできたりするわけです。
ありがたいのですが、ALBに付与するセキュリティグループはどうすればよいでしょうか?
いくつか考えられそうです。
- VPCオリジンの作成時にVPC内に作られるENIに付与されているSGからのリクエストを許可する
- リクエストもとであるCloudFront DistributionのIPからのリクエストを許可する
- VPC全体からのリクエストを許可する
当然1.が望ましいのですが、terraformでVPCオリジンを作成しても、その関連付けられたENIやSGを取得できません。
このため2.の方法を使い、CloudFrontからのリクエストを許可することで通信経路を確保できます。
このマネージドプレフィックスリストは含まれるIPが膨大なので、一つのSGに複数このマネージドプレフィックスリストを使うことはクオータに引っかかります。
HTTPとHTTPSを許可したい…という場面では使えないかもしれませんが、今回はHTTPだけ通せればよかったのでこれを利用しました。
プライベートサブネットで柔軟な構成を作る
ALBを共用する場合、ALBに関連付けられる(ALBが足を伸ばせる)パブリックサブネットはAZ毎にひとつずつまでです。
つまりパブリックサブネットも共用する形になります。
一方でプライベートサブネットには制約は発生しません。
このため、NW構成の柔軟性はさほど失われません。
例えば「環境毎にべつのIPで外部サービスと通信したい」という要件であっても共用のVPC内に環境ごとのプライベートサブネットを作り、そのルートテーブルとして別々のNAT GWを指定する…というような形で対応できます。
この際インターフェイス型VPCエンドポイントは共用のプライベートサブネットを作って関連付けして、インターフェイス型VPCエンドポイントに付与するSGでVPC全体からのアクセスを許可することでプライベートサブネットを共用することなくインターフェイス型VPCエンドポイントを共用できます。
同一VPC内の複数のサブネットにインターフェイス型VPCエンドポイントを関連付けることはできません。
まとめ
ALB共用による効果と注意点
ALBを共用するNW構成によりランニングコストを42%減らすことができました。
インターフェイス型VPCエンドポイントやALB、パブリックIPv4といった居るだけでコストがかかるコンポーネントが多い環境では検討に値するでしょう。
もちろんALBを共用するということは他環境の影響を受け得る構成になるということです。
ノイジーネイバー問題などが発生しないかは注意がいりそうです。
今後の展望
NWを統合するので当然NAT GWなどの統合も進めていくつもりです。
そうすると以前やったTransit GWによるNAT統合もいらなくなる(Transit GWなしで統合できる)ようになりそうです。
それもそれで「居るだけでコストがかかるコンポーネントの削減」なので、積極的に過去の自分が作った構成を破壊していこうと思います。